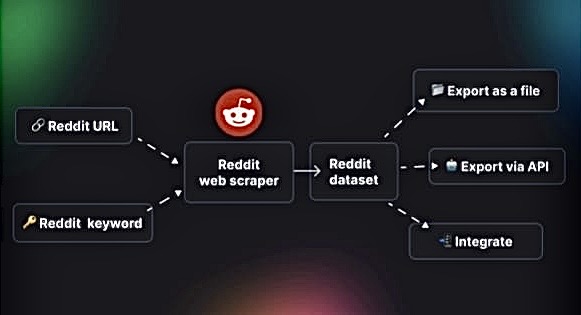
Ever wondered how you can dive deeper into Reddit’s treasure trove of information? You’re not alone.
With its endless threads and communities, the Reddit scraper holds a wealth of insights waiting to be explored. But manually sifting through all that data can be overwhelming, right? That’s where scraping comes in. Imagine having the ability to extract the exact data you need, effortlessly and efficiently.
You’ll discover the secrets of scraping Reddit like a pro. We’ll guide you through the steps, tools, and techniques that will transform the way you interact with this platform. Ready to unlock the potential of Reddit for your personal or professional projects? Let’s get started.
Reddit Basics
Reddit is a vast online community where users share content and engage in discussions. It’s a platform organized by interests, allowing people to connect over shared topics. Understanding its basics is crucial for anyone interested in scraping data.
Understanding Reddit’s Structure
Reddit is divided into sections called subreddits. Each subreddit focuses on a specific topic. Subreddits are like individual forums within the larger Reddit scraper community.
Every subreddit has its own set of rules. These rules guide the behavior and content allowed on that subreddit. Users can subscribe to subreddits they are interested in.
Posts on Reddit are either text, links, or media. Users comment on posts and upvote or downvote them. This voting system determines the visibility of posts on Reddit.
Popular Subreddits To Scrape
Some subreddits have large, active communities. These are great for scraping data. Subreddits like r/news, r/science, and r/technology are popular.
r/AskReddit is another subreddit with engaging discussions. It hosts questions and answers from users worldwide.
r/gaming and r/movies cater to fans of entertainment. They have diverse content, perfect for scraping insights.
Exploring popular subreddits can provide valuable information. It helps understand trends and opinions in different fields.
Tools For Scraping
Reddit scrapers (like PRAW, Pushshift, or third-party tools. Popular options include PRAW and Reddit’s official API. These tools help gather posts, comments, and user information efficiently for analysis or research.
Tools for Scraping Navigating Reddit’s vast sea of information can be a goldmine for insights, but it’s crucial to have the right tools to scrape data efficiently. Whether you’re a seasoned developer or just starting out, there’s a tool out there tailored for your needs. Let’s dive into some of the most effective tools that can help you scrape Reddit data effortlessly.
Python Libraries
Python is a popular choice for web scraping, and for good reason. Its libraries make scraping Reddit seamless and efficient. PRAW (Python Reddit API Wrapper) is a favorite among developers. It simplifies the process of interacting with Reddit’s API and lets you access posts, comments, and more with just a few lines of code. Imagine you want to analyze trending memes in various subreddits. With PRAW, you can easily fetch posts from multiple subreddits, analyze titles, and even gather upvote data. It’s like having a Reddit data genie at your fingertips. Another handy library is BeautifulSoup. While it’s not specific to Reddit, it helps parse HTML and XML documents. You can use it to scrape Reddit’s web pages directly if you want to collect data without using the API. But remember, direct scraping can be against Reddit’s terms of service, so always check the guidelines.
Apis And Third-party Tools
APIs offer a structured way to access Reddit’s data. The Reddit API is comprehensive and provides endpoints for almost everything you might need. From fetching subreddit details to user information, it offers you direct access to Reddit’s vast data. When I first started using the Reddit API, I was amazed at how easily I could pull detailed datasets. It’s a powerful tool that can help you uncover trends and insights you might miss at first glance. If coding isn’t your strong suit, consider using third-party tools like Octoparse or ParseHub. These tools offer a graphical interface to set up your scraping tasks without writing a single line of code. You can visually design your scraping workflow, making it accessible even if programming feels daunting. What kind of data are you interested in? Whether it’s understanding the dynamics of a subreddit community or tracking the popularity of certain topics, these tools can be your gateway to Reddit’s treasure trove of information.
Setting Up Your Environment
Creating a smooth setup is vital for scraping Reddit. Start by installing essential libraries like Python and Beautiful Soup. Ensure you have API access, which is crucial for data retrieval.
Setting up your environment is the first crucial step in your journey to Reddit scrape successfully. Think of it as laying the foundation for a building. Without a solid base, the structure cannot stand. Here, you’ll install software, configure APIs, and ensure everything is ready for action. Diving into this process might feel overwhelming, but breaking it down into manageable steps makes it a breeze.
Installing Necessary Software
To start, you’ll need Python installed on your computer. Python is a versatile programming language that makes web scraping tasks more straightforward. Visit the [official Python website](https://www.python.org/downloads/) to download the latest version. Next, you’ll need to install essential libraries. Use pip, Python’s package manager, to install libraries like praw (Python Reddit API Wrapper) and pandas. Open your terminal or command prompt and type: `bash pip install praw pandas These libraries are key to interacting with Reddit’s data and managing the information you gather. Have you ever tried cooking without the right utensils? It’s not impossible, but it sure makes things harder. The same goes for web scraping without these tools.
Configuring Apis
APIs are the bridge to Reddit’s data. To access this bridge, you need to create a Reddit app. Head over to Reddit’s [developer portal](https://www.reddit.com/prefs/apps) and click on “Create App” or “Create Another App.” Fill in the form with your app’s name, select “script” as the type, and provide a redirect URI, such as http://localhost:8080. Once done, you’ll receive a client ID and secret. These are your keys to the Reddit kingdom. Now, configure your PRAW settings. Create a Python script and input your credentials: python import praw reddit = praw.Reddit(client_id=’YOUR_CLIENT_ID’, client_secret=’YOUR_CLIENT_SECRET’, user_agent=’YOUR_APP_NAME’). This setup tells Reddit who you are and what data you’re allowed to access. Think of it like having a VIP pass to the world of Reddit, offering you insights that regular browsing can’t. Have you set up your environment yet? If not, what’s holding you back? This is the moment to turn your curiosity into action.
Creating A Scraping Script
Creating a scraping script is essential for extracting valuable data from Reddit. This process involves writing code that can navigate Reddit’s complex structure. A well-crafted script helps you gather insights efficiently. Let’s explore how to write basic code and manage errors effectively.
Writing Basic Code
Begin by selecting a programming language. Python is popular for web scraping. Install necessary libraries like Beautiful Soup or Scrapy. These libraries simplify data extraction. Use Reddit’s API to access data legally. Write code to send requests to Reddit’s servers. Parse the HTML to extract information like post titles or comments.
Organize your code for easy reading. Include comments to explain complex sections. Test your script with small datasets. Adjust it as needed to improve accuracy. A clean script is easier to debug and maintain.
Handling Errors And Exceptions
Errors can disrupt your scraping process. Anticipate common issues like connection errors. Use try-except blocks to catch these errors. This prevents the script from crashing. Log error messages for troubleshooting.
Handle exceptions gracefully. Provide fallback options if data is unavailable. This ensures your script continues running. Regularly update your script to adapt to Reddit’s changes. A robust error-handling strategy keeps your data reliable.
Data Extraction Techniques
Reddit scraper is a goldmine for data enthusiasts. Extracting data from Reddit can provide insights into trends and opinions. This process, known as data scraping, involves using various techniques to gather information. These techniques include extracting posts, comments, and more. Once data is collected, it can be filtered and sorted for further analysis.
Extracting Posts And Comments
Start with Reddit’s API. It allows users to access posts and comments. You’ll need to create an API account. After that, use Python libraries like PRAW. This helps in fetching data easily. PRAW simplifies interaction with Reddit. You can pull posts from specific subreddits. You can also retrieve comments related to these posts.
Filtering And Sorting Data
Once you’ve extracted data, filtering is next. Decide which data is important. Use conditions to filter out unnecessary content. Python’s Pandas library can help. It makes data handling easier. Sorting data is also crucial. Arrange data by date or popularity. This helps in understanding trends better.
Data Storage Options
Scraping data from Reddit can reveal valuable insights. But storing this data efficiently is crucial. You need to choose the right storage solution based on your needs. Let’s explore different options for storing scraped data.
Database Solutions
Databases store large volumes of data efficiently. They offer structured formats for easy querying and analysis. Popular choices include MySQL, PostgreSQL, and MongoDB. MySQL and PostgreSQL are relational databases. They work well with structured data. MongoDB is a NoSQL database. It suits unstructured data better.
Relational databases organize data into tables. This makes it easy to retrieve specific information. NoSQL databases store data in flexible formats. This allows for rapid changes and scalability. Choose the best database type based on data structure and growth potential.
File-based Storage
File-based storage is simple and straightforward. It involves saving data in files on a computer or server. Formats like CSV, JSON, and XML are commonly used. CSV files are easy to read and handle. JSON files are great for nested data structures. XML files are suitable for complex hierarchical data.
File storage offers ease of access and portability. It’s ideal for small-scale projects or initial data collection. For larger datasets, consider file management tools. They help organize and retrieve data efficiently.
Analyzing Scraped Data
Analyzing scraped data from Reddit is a powerful tool. It helps uncover insights that drive decision-making. By diving into the data, we can identify emerging trends. We understand public sentiment on various topics. This section explores how to analyze Reddit data effectively.
Identifying Trends
Trends show what topics gain popularity on Reddit. Scraping data helps spot these trends early. Look for recurring topics or keywords. Check posts with increasing interaction. This reveals shifts in user interest. It also highlights emerging discussions. Trend analysis guides content creation and business strategies.
Sentiment Analysis
Sentiment analysis deciphers emotions in Reddit discussions. This involves examining the tone of posts and comments. Use text analysis tools to categorize sentiments. Determine if users feel positive, negative, or neutral. Understanding sentiment helps gauge public opinion. It also aids in predicting market behavior. Sentiment analysis is crucial for brand reputation management.
Legal And Ethical Considerations
Scraping Reddit involves understanding both legal and ethical aspects. Follow Reddit’s API terms to avoid violations. Respect user privacy and avoid collecting personal information.
Scraping Reddit can be a goldmine for data enthusiasts, but it’s not without its legal and ethical hurdles. Understanding these considerations is crucial to ensuring that your data collection practices are above board. Ignoring them could lead to unwanted consequences, both legally and ethically.
Reddit’s Terms Of Service
Reddit’s Terms of Service are clear about what is allowed and what isn’t. They specifically prohibit scraping without prior permission. Violating these terms could lead to your account being banned or legal action. To scrape Reddit legally, consider using Reddit’s official API. The API is designed to help users gather data while respecting the platform’s rules. Always review Reddit’s API documentation to ensure compliance.
Ensuring User Privacy
User privacy is a major concern when scraping data. Reddit users often share personal stories and sensitive information, expecting a level of anonymity. Always ask yourself if the data you are collecting could potentially harm someone. Anonymize any data that could identify individuals and avoid collecting more information than necessary. Respect the community by being transparent about your intentions. If possible, engage with the Reddit community and explain your purpose. This approach not only builds trust but can also offer valuable insights into the data you aim to collect. Remember, just because you can scrape certain data doesn’t mean you should. How would you feel if your personal data were collected without your knowledge? Use this perspective to guide your data scraping practices.
Troubleshooting Common Issues
Facing challenges while scraping Reddit can be common. Ensure your tools are updated for smooth data extraction. Check Reddit’s API limits to avoid access issues.
Scraping Reddit is a powerful way to gather insights, but it often comes with its own set of challenges. You might encounter issues that can halt your progress. These common hiccups can be frustrating, but they also offer a chance to learn and adapt. Let’s tackle some of the most frequent problems you might face and find solutions that keep your scraping journey smooth.
Overcoming Api Rate Limits
Reddit’s API imposes rate limits to manage traffic and ensure fair usage. These limits can restrict the number of requests you can make in a given timeframe. You might feel stuck when your script is throttled, but there’s a simple workaround. Consider adding sleep intervals between your requests. This reduces the frequency of your calls and helps you stay within the limits. Experiment with different intervals to find what works best for your needs. A delay of a few seconds can significantly improve your request success rate. Another tip is to use OAuth authentication. This often provides higher rate limits than anonymous requests. If you haven’t tried it yet, integrating OAuth might be the upgrade you need for smoother operations.
Dealing With Captchas
CAPTCHAs are another obstacle you may encounter when scraping Reddit. These annoying puzzles can disrupt your workflow, but there are ways to handle them effectively. You can use CAPTCHA-solving services, but this can also come at a cost. If you’re just starting out, try adjusting the frequency of your requests. Slowing down your request rate can sometimes prevent CAPTCHAs from appearing. Have you considered using a proxy server? They can distribute your requests to multiple IPs, reducing the likelihood of CAPTCHAs. This is a clever trick that often goes unnoticed, but it can make a big difference. What techniques have you found effective in overcoming these challenges? Your experience may reveal insights that others can learn from.
Frequently Asked Questions
Is Reddit Scraping Allowed?
Reddit scraping is generally not allowed. Reddit’s API and terms of service restrict data scraping. Always check Reddit’s policies before scraping. Unauthorized scraping can result in account suspension or legal action. Use Reddit’s API for data access instead.
How To Completely Wipe Reddit History?
To completely wipe Reddit history, delete individual posts and comments manually. Clear your search and browsing history in Reddit settings. Use third-party tools like “Nuke Reddit History” for bulk deletion. Deactivate your account for complete removal. Always back up important data before proceeding.
How To Cut Off Nsfw On Reddit?
Go to Reddit settings, choose “Account Preferences,” and uncheck “I am over 18 and willing to view adult content. ” Save changes to block NSFW content.
Is Web Scraping Profitable On Reddit?
Web scraping on Reddit can be profitable if done ethically and legally. It helps gather valuable data insights. Always respect Reddit’s terms of service to avoid legal issues. Focus on extracting data that provides business value, like market trends or user sentiment.
Use this information to enhance strategies or product development.
Conclusion
Scraping Reddit opens many doors for data enthusiasts. It helps gather insights quickly. Always respect Reddit’s rules while scraping. Choose the right tools for efficient results. Understanding the platform’s API can be a game-changer. Stay updated with any API changes or community guidelines.
Protect your data and privacy. Learn from mistakes and improve your technique. With practice, the process becomes easier. Enjoy exploring Reddit’s vast world of information. Remember, ethical scraping benefits everyone. Dive in, and see what valuable data awaits. Stay curious, and keep learning from your experiences.